近日,重庆大学艺术学院音乐系教师苏勤研究团队在国际核心期刊《Journal of Voice》(SCI一区,JCR分区)发表题为“Adopted Singing Voice Evaluation Models for Work Efficiency in the Recording Industry”的学术论文。《Journal of Voice》作为声音与嗓音科学领域顶级期刊,长期聚焦声乐医学、技术及声音教育研究。音乐系优秀校友黄雪洁博士为论文通讯作者,苏勤为论文第一作者。该研究获得重庆大学教育发展基金会项目的资助。

论文聚焦人工智能与声乐科学的交叉领域,提出了使用声音信息维度构建歌唱评估模型,为音乐产业工作流程优化提供了创新解决方案。在目前的音乐学科体系和声乐教学框架中,音乐教育界输出的人才能够满足音乐市场对声乐的基本需求。然而,在音乐产业中,使用声音高效工作一直是教学未能填补的空白。实现产业化的精准与高效的歌唱,需要量化歌声的参数,而当前却没有声音综合的量化模型提供给声音筛选者进行参考。苏勤老师与黄雪洁博士团队的研究以录音行业中的声乐效率问题为切入点,量化了歌唱的声学分析,建立了以效率为导向的歌声筛选模型。团队通过提取录音干声的方式,并对采样声音分段切片,使用Praat 等语音信息分析软件提取了每个Singing Duration (歌唱节点) 的Pitch Deviation (音高偏离),Rhythm consistency (节奏连贯),Intensity (强度), Vibrato extent (颤音幅度), Voice Quality (声音质量),Dynamic Range (动态范围) 以及Rework times (返工次数)。
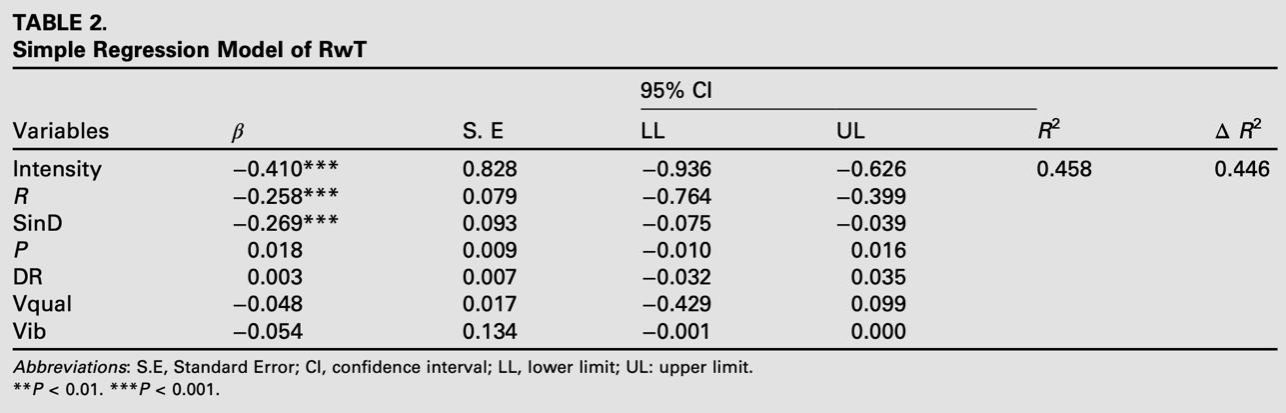
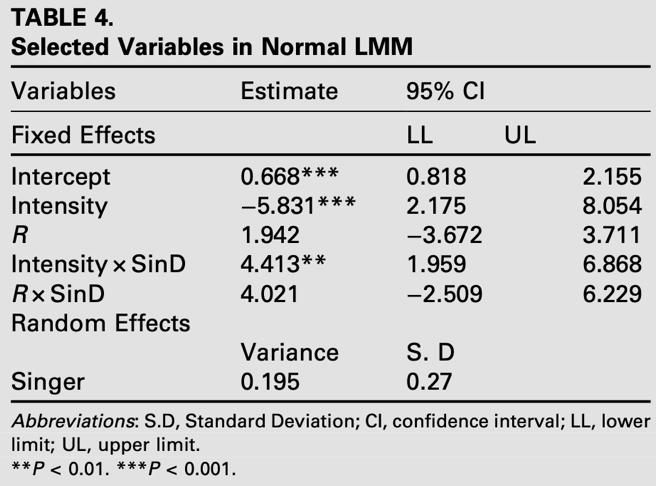
线性回归分析中显示,强度是预测返工次数最具影响力的变量(β = −0.410,P < 0.001)。强度值越高,返工次数越少,那么歌唱效率越高。这一发现说明了歌声的强度在歌唱效率预测中的重要性。在后续的交互效应验证中,她们发现了声音强度与歌唱节点的交互效应显著,共同影响了歌唱效率。通过对比Normal LMM (线性混合模型) 和SLRM (简单线性回归模型)两者,并采用AIC(赤池信息准则)策略进行挑选,发现LMM在拟合度上更加优化。研究团队通过歌唱发声的理论与歌唱节点的呼吸规律结合,指出声乐实践者通过高音练习的过程,实质是在练习嗓音的强度与声音的密度。这为歌唱者与教学者提供了量化式了解歌声的可能,并能应用在歌声评分系统、AI效率预测、人机共同评价机制中。
该项研究成果体现了“艺术+科技”的跨学科协作特色,是音乐系教师团队在声乐科学研究领域的一大突破,凸显了艺术学院在交叉学科建设上的国际前瞻视野。









 关注我们
关注我们